
![The Thing [ ]](https://substackcdn.com/image/fetch/w_152,h_152,c_fill,f_auto,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffb90d42c-1ded-4d1e-95df-fecf58f5ab0b_1400x1400.png)

What a week! 😉
What we’ve learned🤓
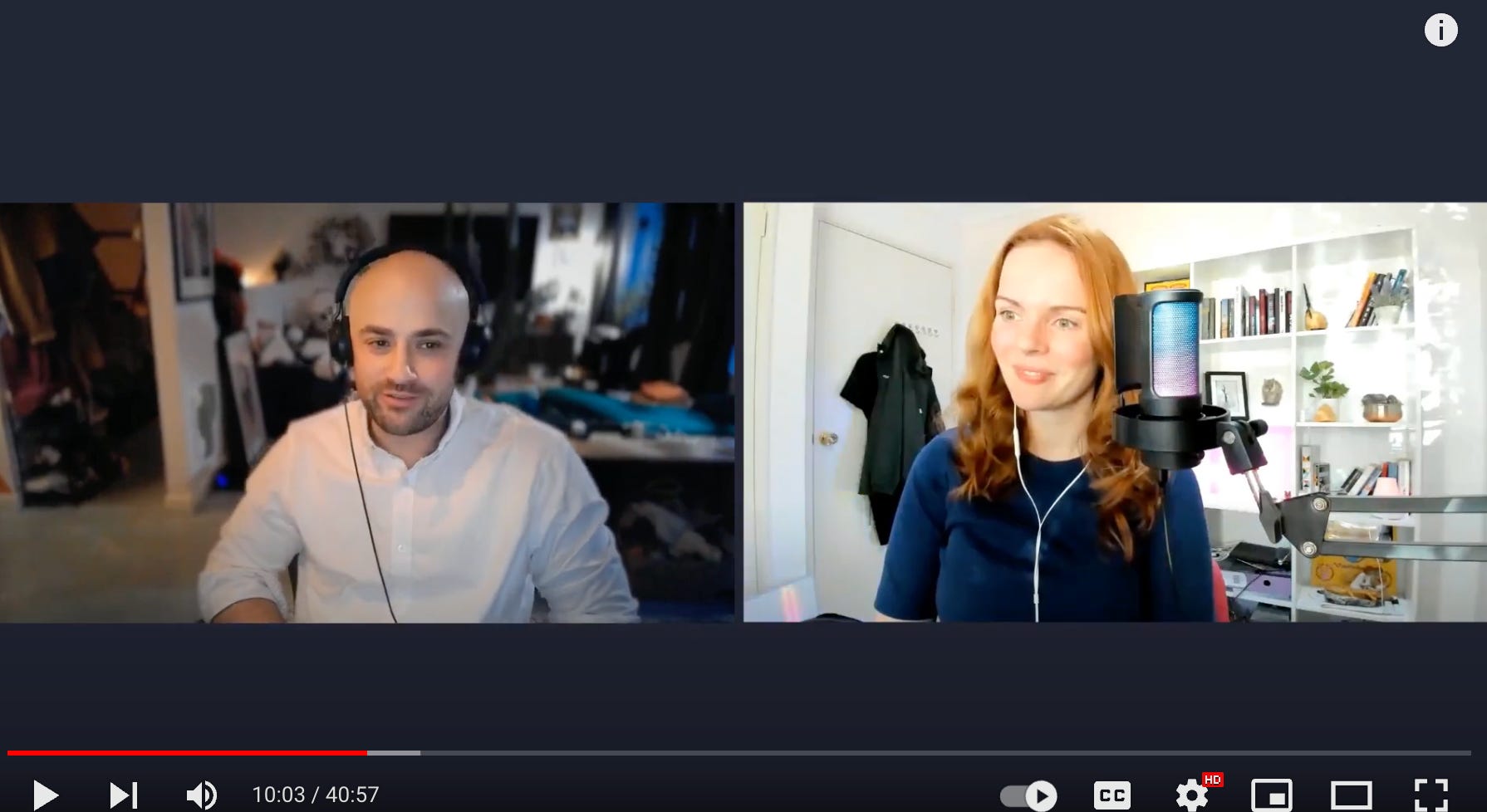
The recent podcast with Kyle Legare, I don’t want to give everything away but it was a wonderful conversation that showed that technical background (and ability) aren’t necessarily barriers to entry for trying llms anymore.
Is it all too much?
Recently I asked on Linkedin how others are feeling about the state of overwhelm. A running theme in conversations I’ve been having is “I wish I could distil it down, there’s too much to focus on”.
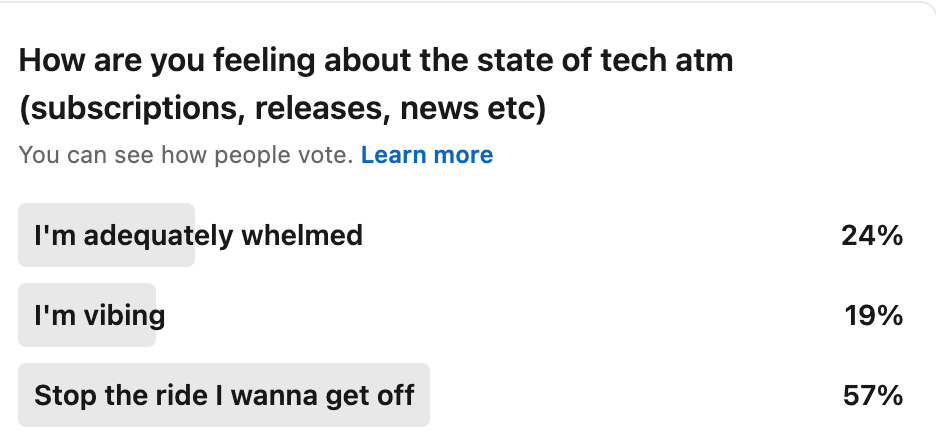
At the end of last year- I tallied up how many tools and subscriptions I’d signed up for. The answer (after scouring online receipts and emails) was 174…..
mentioned it may be an idea to not be “everywhere” online. It gave me pause. It made me think about the tendency to -
Such is the life of an early adopter though! To *stay* on the bleeding edge of innovation/ adoption or cool shit happening- you sacrifice things like sleep, perfection and occasionally your sanity.
A great reminder came in the comments section of my first “build in public” update post whereOptimise for short attention spans
Hack together fixes (accumulating a sort of “non-tech”-debt)
Optimise for the algorithm
Want to know the nitty gritty but only having time for “cliff notes”
Another little poll I did confirmed the above hypothesis somewhat, that folks want to know everything they can about subjects (FOMO, am I right?)
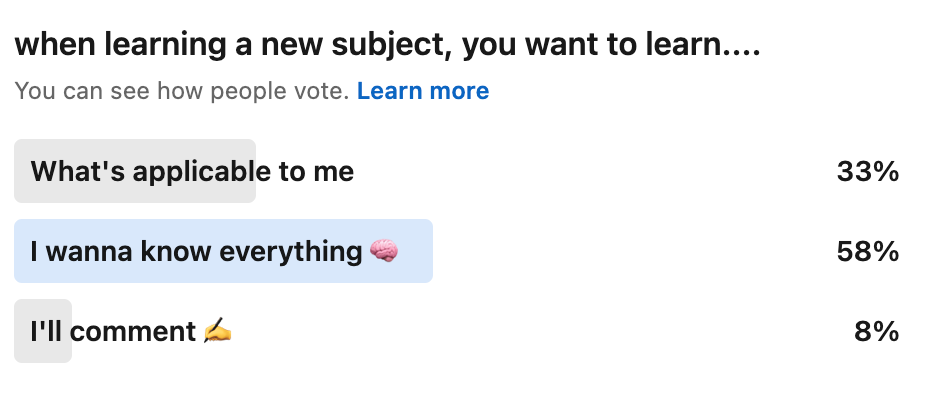
Which brings me to another poll…
but not before this post by

Quick news🗞️
The Jan team has been making strides with their releases and shipping like crazy.
This research paper from last year from a follower of mine Alfonso de la Fuente Ruiz-PhD was a really interesting read -
The paper talks about the development and management of Infrastructure-as-Code (IaC) through open-source software, addressing company concerns about potentially aiding competitors or losing proprietary secrets. It gives a framework for open sourced IAC projects.
Explaining “More Agents is all You Need” in simple language.
The Tencent research team found that making language models better is as simple as using more small programs called agents.
They used a special way to pick the best answer by asking many agents and going with the most popular choice. (a way to do this “in the wild”? Try https://chat.lmsys.org/)
When they added more agents, even the smaller models could do as well or better than the big ones. For example, a smaller model did better on a test than a bigger model.
But, there's a point where adding more agents doesn't help anymore, especially for very hard tasks. Also, if a model can't do something, just adding more agents won't fix that.
This method is good because it's easy to use and can be mixed with other ways to make models even better.
They suggest specific ways to use more agents smarter, like breaking down tasks or using different models for different parts of a problem.
Overall, adding more agents is an easy way to make language models work better, but it works best under certain conditions.
Was that a cool explanation? Want to share
Future Happenenings
I’m going to be on a few podcasts! 🥹 make sure you’re following
atComing up soon- a great chat with Mike Bird of Open Interpreter

A collaboration with the wonderful
Spencer of AI Supremacy (and multiple other publications)Something else I’m excited about… the release of Aya

Coheres new open-source generative AI model can follow instructions in more than 100 languages.
Why you should care
Most models that power today's generative AI tools are trained on data in English and Chinese, leaving behind potentially billions of people.
More on the project
Cohere for AI, the nonprofit AI research lab at Cohere, on Tuesday released its open-source multilingual large language model (LLM) called Aya.
It follows a year-long development involving 3000 researchers across 119 countries. I’m hoping to have the Head of Cohere for AI, Sara Hooker on the podcast soon to talk about the project (watch this space)
Wanna keep the party going?
Thank you for reading 🤘 (un)supervised learning — your support allows me to keep doing this work.
Ways to help out
Share 🤘 (un)supervised learning. When you use the referral link below, or the “Share” button on any post, you'll get credit for any new subscribers (plus stuff gets read!)
Recommend someone for the pod- Have someone in mind who’s doing cool things across AI or opensource? Send them this way!
Follow and rate and all that jazz- Spotify, Youtube and Apple podcasts are a learning curve but I know the algo beast loves a rating, yours helps!
Until next week,
Stay curious





Offline Chatgpt,new episode drop and more=better?